

Ok, so now we have all the hardware selected, let’s talk OS and storage configurations, a lot of it comes down to personal preference and hardware you want/need to buy!
This post is part of a multi-part article.
You can find the main index here
OS choice
A lot of Operating Systems can be used on the server, all software required can be run on Windows or generally available Linux distributions.
Personally I like using the Debian based Ubuntu and these guides will be written using Ubuntu 16.04 LTS server edition. Since this will be a pure server, we don’t need a GUI or anything like that, saving memory and CPU power. But the choice is yours!

Storage choices
Here it becomes a bit more complicated or rather, choices need to be made to suit your situation and needs.
Selecting the right HDD’s to buy
When buying storage that needs to run 24Hrs a day, 2 values are important, cost per Gigabyte (6TB to 8TB are currently the sweet spot) and power usage. Combining those factors with on-hours (which is going to be 24Hrs a day this case) will give us the best disk to buy.
Power costs
Between a disk that uses 3 watts idle or 6 watts idle, with 20 cents per kWh of power, there is 5 euro cost difference per disk per year to just run it. Counting 5 drives for 3 years that comes down to ~80 euro’s of power costs difference between older traditional and newer generation helium disks, that alone might make up the difference to buy the new model.
Next to the power savings these new models introduce, they also have a lot bigger caches and run at 7200RPM speed! That’s why for 24Hr usage the current 10TB Helium disks are the most cost effective. Starting with 2x 10TB disks now instead of 4x4TB disks also gives you the ability to expand/upgrade in the future if needed without having to add another USB cabinet.
Disk expected read failure and RAID5/RAIDz1
Every disk has a number of transferred bytes after which it should, statistically, give a read error on the data. There has been a lot of discussion about this in the recent years because disks have been growing, but this number was not increasing.
Back in the 2000’s it used to be 10E13 which basically stands for 1100GB. That means that if a disk reads 1100GB, somewhere around that number it should have given a read error, statistically.
Since we’ve moved on to 1TB disks and larger, that number has remained pretty static around 10E14 which means that every 11TB an error should occur. This is also when people starting saying RAID5 was not safe anymore.
Why large RAID5/RAIDz1 arrays or large disks are a problem
The reason is this, let’s say you have 5x8TB in RAID5/RAIDz1 and a disk fails so you need to a rebuild. During the rebuild it needs to read 32TB of data to regenerate the failed disk. If we measure that amount of data over all the disks, in theory we have a failure possibility during the rebuild of about 256%! Although these are statistic and most often, in the real world, it would probably survive just fine, it’s way too high to really trust. Because of this RAID6/RAIDz2 was invented which lowered this number below 1% again.
Very recent consumer disks have gotten better
But recently, some of the newer types of disks , especially the Helium filled one’s (Like the Seagate Ironwolf series), have started shipping with an error rate of 10E15. That’s 1 bit per 1.000.000.000.000.000. That number says that around about ~125TB of reads, an error should occur. So, if we then create an array like 3x10TB, during a rebuild and reading 20TB of data there is a 16% chance that another disk should fail during the rebuild.
You need to decide for yourself how much your backups are worth.
Check the disk surface before using the disks
I made a video about the Seagate Ironwolf 10TB disks and some checks you can do to make sure they are okay a little while back, check it out over here.

Operating System Storage
For the OS I will use the onboard 32GB eMMC. I’m not sure how long it can/will last but time will tell. To prevent a total system failure I will use a 32GB SDcard to which I will periodically (Every month or maybe every quarter?) DD the system partition to.
Next to that I will also setup a backup to the disk array that runs more regularly to keep track of recent changes. In the case of a failure, you can DD what’s on the SDcard back or even just boot from it. And then restore any newer changes with the most recent backup on the disk array.
In theory the OS disk does not contain any important information but making it easier to bring back the server if the eMMC memory fails is a good strategy anyway.
If you need it to be more highly-available than that, you could use an M.2 SSD/2.5″ SSD and create a mirror with the eMMC memory.
Data Storage configurations
The Minio S3 storage software we are using on the server supports erasure coding natively but it does not need to be used, you can use any form of underlying storage you desire, I’m a fan of ZFS for instance, but anything goes really, if you wish to use MDADM with EXT4 or maybe BTRFS, all of those are valid and will work.
Personally I believe we should at least protect against the failure of a single disk. Since it’s home backup storage I believe protecting more is nice but it also raises the cost quite significantly, but it all depends on your needs.
Below I will discuss a few different configurations from a simple mirror setup to a more complex ZFS usage case and the native Minio erasure coding choice. Hopefully that will help everyone build what they need or at least give them inspiration as to what is possible.
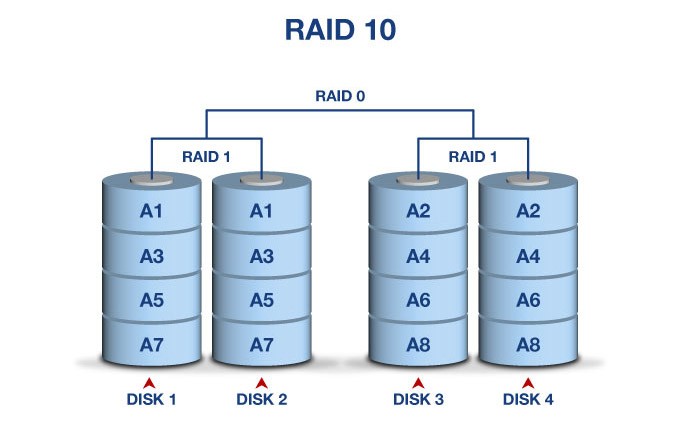
A simple mirror (MDADM)
The “oldest” type of setup would be an MDADM mirror (min 2 disks) or a parity (RAID5, min 3 disks) setup with an EXT4 or XFS volume on top.
Although this is very basic, for lower capacity servers this should work just fine. I personally do not use MDADM anymore since newer options such as ZFS and BTRFS have become available, they are much more feature rich and do a better job in protecting against bit rot and too long rebuild times.
ZFS and BTRFS Storage
Before I mentioned bit rot and long rebuild times. Since disks have been growing larger and larger the chance of a failure while data is at rest, or a rebuild is taking place, has also become much larger. To prevent these issues new forms of “RAID” where needed.
These new storage techniques use features such as Copy On Write for instance. COW means whenever a file gets written or modified, the data gets written to a new place on the disk as to not overwrite the original data. That way if during the write there would be corruption, the original file/blocks would still be available.
With these new techniques ZFS and BTRFS was born. ZFS was “first” but had some issues getting traction on Linux because of certain licensing issues, but that has long been resolved and I’ve been using ZFS on Linux for years now to great success! But BTRFS is also gaining some traction recently since it’s touted as the next filesystem for Linux systems and it has some strong points going for it, but currently it’s less mature than ZFS is in my opinion.
ZFS is everything all-in-one, a “RAID” controller, a volume manager and a filesystem. That allows it features such as very efficient snapshots, quotas or built-in compression and deduplication.
ZFS is also particularly interesting because it’s very well suited for running on “bare” disks without a RAID controller in between. The external USB3 disk cabinet mentioned before passes-through S.M.A.R.T. information of all the disks individually so it all makes it a good fit!
Gives you the ability to use quotas
As I mentioned, I’m a fan of ZFS and use it where possible/useful. In this use case I like using the quota feature to set quota’s between the different tenants the system will have. This will be explained in more detail in the server software setup part.
ZFS ZIL and L2ARC caches
While yes, ZFS gives you the ability to use ZIL (write) and L2ARC (SSD read) caches and the server we’ve chosen accepts 2.5″ disks and M.2 SSD’s I advise against using it. These features eat system memory to do so and I do know know it using it would be beneficial at all.
ZFS Mirror
As with the MDADM mirror above a ZFS mirror is 2 or 4 disks in a mirror or in RAID1/10. Personally, if you are going to use mirrors, I would not use the MDADM variant anymore (except maybe for system disks) and use the ZFS variant.
Also ZFS allows you to create multiple mirrors and use them as a single filesystem, giving you a form of RAID10 but with infinite growth possibilities. This does come at the cost of 50% of your available disk space for security though.
A big advantage of using multiple mirrors is that I/O performance scales with more disks.
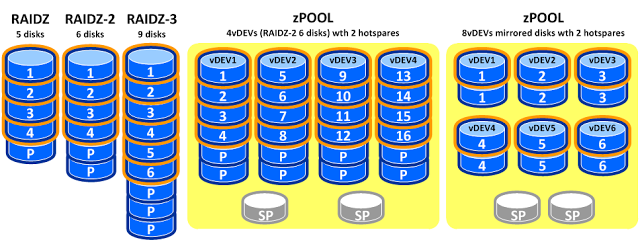
ZFS RAIDz1 (RAIDz2/RAIDz3)
Another way to configure the disks you buy is using RAIDz. RAIDz uses a striping method like RAID5 or RAID6 does.
Low Random I/O performance
There are however some differences between RAID and RAIDz, the main difference to be aware of is that RAIDz uses a variable stripe size. What that means is that all files are always distributed over all disks, effectively making a single RAIDz perform at the speed of a single disk. So random I/O performance does not scale with using multiple disks. Sequential I/O does scale with the disks in the RAIDz.
So random I/O performance will not be great, but the question is, do we really need much of it? I don’t believe so, so I see it as an option!
RAIDz1 can be risky (RAIDz2/z3 are fine)
Another thing to take into account is that RAIDz1 is susceptible to the same rebuild issues as with (MDADM) RAID5 while using big disks and/or arrays. The chance that another disk in the array should statistically fail can be too high and thus unsafe using it with larger disks/arrays.
Take a look at the top of this article where I explain why and what to look out for. RAIDz1 can be an ok option, but you need to know when and how, so you can buy the right hardware.
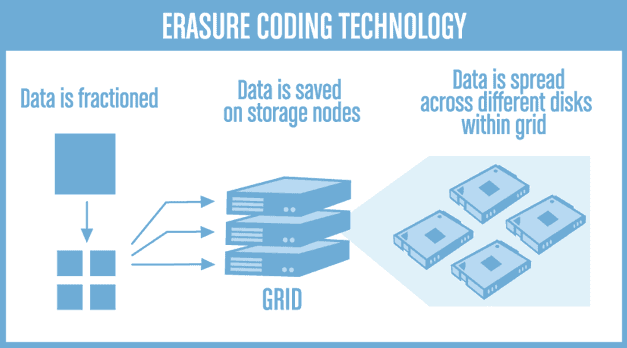
Minio Erasure Coding
Minio, the S3 storage backend we’ll be using also has built-in storage protection against failing disks and bit rot. So instead of relying on your storage system to do so (Like ZFS or BTRFS) you can let Minio handle it all.
Erasure coding is a bit complex to explain but basically it works in the principle of distributing data across multiple disks or nodes with data and parity parts.
To start, it requires at least 4 disks and you will lose 2 disks to parity. So 50% is used for redundancy/safety, quite a hefty price for data that is already a backup of original data somewhere, but that is my opinion.
Once you start scaling up though and use 5 disks, things get more interesting because you are still only using the space of 2 disks for the protection. So with 5x 10TB disks and erasure coding you get 30TB of usable space, the same as RAID6 or RAIDz2 would give you with the same disks. I believe there is an advantage of using Erasure coding above RAID6 and RAIDz2 though. RAID6 can suffer from bitrot so is basically a no-go in the current age and RAIDz2 probably has a lot worse random I/O performance because of the way ZFS works.
So Erasure coding, depending on your setup, can be a good choice. It would also mean you don’t have to learn any ZFS for instance. Just create and mount some XFS volumes, present them to Minio and you’re done, Minio takes care of the rest!
*Currently Minio does not support setting a quota, that means you cannot set Quota’s between your tenants like you can with ZFS.
Time to buy some disks
Hopefully that explains a little bit the choices you have in buying disks and how to use them.
Using ZFS does give me the ability to use ZFS quotas to keep potential tenants in line if needed. Or you could maybe use different payment classes for different quota sizes.
Continue on to the next article to follow along with how to configure the server!
