

I’ve been using Seagate IronWolf disks for a few years now and currently have about 20 in service, most of those are the 10TB (and 12TB) Non-Pro (ST10000VN0004) variety. Most of my experience with them has been great so when the new server build came along I bought a few more to run as my main ZFS pool. Sadly, things didn’t go exactly as planned, but I think I was also able to fix it, so let’s see what happened!
Before writing this post about this issue I started a topic on ixsystems.com since there where several post describing this problem already. Since writing there I believe enough information is now known that I can “release this to the public”. If you are looking for a condensed version take a look at the link (It’s the forum post). The topic might also contain some extra information not in this article.
Full article but also in video form
This is a full article about the issue but I have also made a video about it, you can chose what to read/watch/view!
The issue had been seen before, but very rarely
As mentioned, I have lots of these disks running in various different servers and up until now I haven’t really experienced any issues with them. I had one friend who sometimes had some CRC errors in his ZFS setup but in my own old server I had 2x 10TB (ST10000VN0004) and those never had an issue, the same with my “DIY Cloud Backup” solution, that has 5 of these disks in an external enclosure, 0 issues.
When these issues would occur for him they would show up as CRC errors in ZFS but no real reason why, so after troubleshooting for a while I wrote it off as a fluke. He also had different IronWolf 10TB disks in his setup and it always seemed to be a pair that gave these issues but even external testing with a write, read, checksum test showed 0 errors but ZFS would still complain sometimes. We tried the regular cable swap, a different PSU, changing ports and even controllers, nothing really made a difference. A very odd and isolated case I thought and never really understood what was going on.
Suddenly, I had this issue too
Moving on and building my 8x10TB Seagate IronWolf ZFS Mirror pool like discussed in this video, all worked well and thus I started moving over my data.
During this move however errors started popping up. The disks where in the hot swap bays of my new server and connected to one of two LSI SAS2008 based cards running the newest 20.00.07.00 firmware. After migrating about 20TB of data I was left with the following:
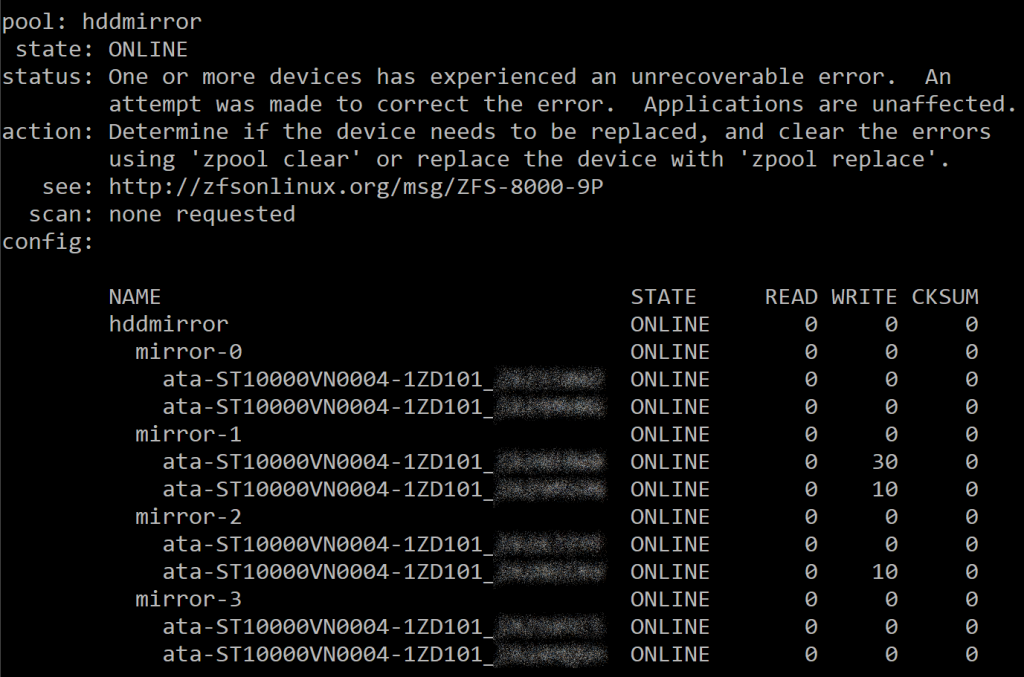
As you can see I had write errors on several disks. These didn’t all happen at the same time but over time while I was copying.
Checking with “zpool events” we see a similar pattern:
Sep 6 2019 05:40:24.133822755 ereport.fs.zfs.delay Sep 6 2019 05:40:24.133822755 ereport.fs.zfs.delay Sep 6 2019 05:40:24.133822755 ereport.fs.zfs.delay Sep 6 2019 05:40:24.133822755 ereport.fs.zfs.delay Sep 6 2019 05:40:24.133822755 ereport.fs.zfs.delay Sep 6 2019 05:40:24.133822755 ereport.fs.zfs.io Sep 6 2019 05:40:24.133822755 ereport.fs.zfs.io Sep 6 2019 05:40:24.133822755 ereport.fs.zfs.io Sep 6 2019 05:40:24.133822755 ereport.fs.zfs.io Sep 6 2019 05:40:24.133822755 ereport.fs.zfs.io Sep 6 2019 05:40:24.133822755 ereport.fs.zfs.delay Sep 6 2019 05:40:24.133822755 ereport.fs.zfs.delay Sep 6 2019 05:40:24.133822755 ereport.fs.zfs.delay Sep 6 2019 05:40:24.133822755 ereport.fs.zfs.delay Sep 6 2019 05:40:24.133822755 ereport.fs.zfs.io Sep 6 2019 05:40:24.133822755 ereport.fs.zfs.io Sep 6 2019 05:40:24.133822755 ereport.fs.zfs.io Sep 6 2019 05:40:24.133822755 ereport.fs.zfs.io Sep 6 2019 05:40:24.133822755 ereport.fs.zfs.delay Sep 6 2019 05:40:24.133822755 ereport.fs.zfs.io
And checking in dmesg, it became clear there where hardware errors that where occurring:
[ 970.494552] print_req_error: critical medium error, dev sde, sector 7814019808 flags 0 [ 974.249856] mpt2sas_cm0: log_info(0x31080000): originator(PL), code(0x08), sub_code(0x0000) [ 974.249865] mpt2sas_cm0: log_info(0x31080000): originator(PL), code(0x08), sub_code(0x0000) [ 974.249871] mpt2sas_cm0: log_info(0x31080000): originator(PL), code(0x08), sub_code(0x0000) [ 974.249875] mpt2sas_cm0: log_info(0x31080000): originator(PL), code(0x08), sub_code(0x0000) [ 974.249896] sd 6:0:4:0: [sde] tag#2376 FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_SENSE [ 974.249901] sd 6:0:4:0: [sde] tag#2376 Sense Key : Medium Error [current] [descriptor] [ 974.249907] sd 6:0:4:0: [sde] tag#2376 Add. Sense: Unrecovered read error [ 974.249915] sd 6:0:4:0: [sde] tag#2376 CDB: Read(16) 88 00 00 00 00 01 d1 c0 7a 00 00 00 02 00 00 00 [ 974.249919] print_req_error: critical medium error, dev sde, sector 7814019808 flags 0 [ 1090.988519] sd 6:0:4:0: [sde] tag#2427 FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_SENSE [ 1090.988531] sd 6:0:4:0: [sde] tag#2427 Sense Key : Medium Error [current] [descriptor] [ 1090.988537] sd 6:0:4:0: [sde] tag#2427 Add. Sense: Unrecovered read error [ 1090.988541] sd 6:0:4:0: [sde] tag#2427 CDB: Read(16) 88 00 00 00 00 01 d1 c0 7a 00 00 00 02 00 00 00 [ 1090.988545] print_req_error: critical medium error, dev sde, sector 7814019808 flags 0 [ 1094.799434] sd 6:0:4:0: [sde] tag#1083 FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_SENSE [ 1094.799443] sd 6:0:4:0: [sde] tag#1083 Sense Key : Medium Error [current] [descriptor] [ 1094.799447] sd 6:0:4:0: [sde] tag#1083 Add. Sense: Unrecovered read error [ 1094.799451] sd 6:0:4:0: [sde] tag#1083 CDB: Read(16) 88 00 00 00 00 01 d1 c0 7a 00 00 00 02 00 00 00 [ 1094.799456] print_req_error: critical medium error, dev sde, sector 7814019808 flags 0
Well, that certainly doesn’t look good!
Wait a minute, that can’t be right?
Before using any disk I subject them to a full verify pass using a separate PC. This is a full 14Hr pass of HDAT2 which verified that each disk was 100% ok before using it. Actually, I’ve never had one of the Seagate IronWolf 10TB or 12TB disks fail me in this test or during service, QC in the factory must be really good (I’ve had different experiences with other brands).
Now if one disk would have errors, ok, that can happen. But this is 3 disks showing errors, that’s highly unlikely, so what’s going on?
Problem gets worse
So I decided to run some ZFS scrubs to see what the effect of those would be. I don’t have any screenshots of that but the same issue as my friend had been having appeared, suddenly several disks would randomly show CRC errors but also read or write errors would occur. Checking with dmesg it seems that the controller encountered an issue where the disk would not answer and after waiting a little bit the controller would reset that disk and everything would be fine again.
I performed several scrubs and while no data was lost or corrupted, each time one or more disks would generate some amount of CRC errors just like my friend had been having! What is going on here…..
LSI/Avago controller related? Per disk chance?
I haven’t been able to form a 100% certain answer to this question. With my friend I believe we tested motherboard ports and LSI ports and he would always have these errors and in my old server I believe the disks where also connected to my LSI controller and there I had 0 issues.
So I am as of yet still unsure if it is LSI controller related or not. I’m inclined to say yes, but I am not 100% sure. Also I’m not sure if it’s only certain disks that show this problem and others don’t. That would concur with what I’ve seen but that’s still a weird conclusion.
What I do know for certain is that the errors occur while the disks are connected to these controllers while otherwise these controllers are held in high regard as functioning well.
Potential Workaround “Fix”
A potential fix was presented again on the ixsystems forum. One of the forum members had figured out he would no longer have issues if he disabled NCQ for the disks. This was something that had to be done each boot but could be scripted. If this worked that would be great, without NCQ performance would be a bit lower, but ok.
I didn’t get around to testing this but it did help in getting more information!
More hints appear…
But then I found a topic on the Synology forum! This topic was about Synology turning off writing caching for these specific drives a few Synology software versions back because of “stability issues”. Hmm, interesting!!
The exact issue was described as “flush cache timing out bug that was discovered during routine testing”. Hmm, that sounds a lot like the same issue as several members on the ixsystems and on reddit where describing and also what I’m seeing in my logs!
Seemingly this had been going on for a while but recently someone from Seagate started replying to the topic and recently it was mentioned that new firmware was now available after which, combined with a Synology update, would re-enable the write cache and fix this issue on these drives.
The actual Fix!
Probably what you have been waiting for, this issue has been fixed in a new SC61 firmware that Seagate has released. All Seagate IronWolf 10TB drives I have ever received, even the examples I bought recently came with the SC60 firmware.
Checking Seagate’s website, there is no firmware listed but there where links in the forum post, I have copied these links and they are available at the end of this post.
Let’s try this immediately!
Since I still had all my data in backups I immediately flashed one of my disks from the original SC60 firmware to the SC61 firmware.
After flashing one of the disks I started a scrub and ZFS found no issues with the data still on the drive, ok! So I flashed all my disks and was able to start my pool normally without any data loss so I started testing.
I was able to run 2 scrubs and write over 10TB of data to the pool now with 0 errors!
*During the first scrub ZFS found some CRC errors but I believe those to have been caused by the issue earlier and that those just hadn’t been fixed yet, I was able to run the 2 scrubs mentioned above after fixing those.
Working for me!
Ok, to make sure this is actually a fix working for everyone I created the before mentioned ixsystems.com post.
For myself I am now running for about a month with the new firmware and having done lots and lots of tests during that period not a single error has occurred anymore so I believe the new SC61 firmware fixes this issue for good. Also important, I have noticed no negative side affects regarding this new firmware, speed and everything else is still great!
Upgrading your own drives
If you are running SC60 firmware on a 10TB Seagate IronWolf drive (Pro or Non-Pro) I recommend updating the firmware from SC60 to SC61. But, a word of warning, I’m just some random guy on the internet and this new firmware worked for me, in my case, and with my issues (and also for the people in the forum topic), upgrading to this new firmware on your hardware is always at your own risk, make sure you have backups!
You can download the firmware files directly from Seagate:
Firmware for IronWolf 10TB ST10000VN0004
Firmware for IronWolf Pro 10TB ST10000NE0004
Ending remarks
These drives have been available since 2017 with the SC60 firmware it seems. Seagate has only now released this new SC61 firmware publicly (or well, it’s still not available on their website) fixing this issue so that’s a bit late in my opinion. Still, it’s good news that a fix is now available which seems to fix these issues.
As far as is known by me right now is that this issue only occurs with the 10TB variant of these drives, but if you have a different experience, please make sure to comment!
As I mentioned before, I love these IronWolf drives in a lot of other regards (Speed, power usage, etc.) so I would still recommend them above other brands if you are looking for fast, reliable and cheap storage. If you are however experiencing these issues, make sure to apply the firmware update!
I have 3 10TB Ironwolf ST10000VN0004 drives, but when I put their SN in Seagate’s Download Finder, it tells me there’s no newer firmware available. (It also says the model number is ST10000VNB004.) The drives are labeled as FW SC60. I’ve never caught them showing errors, but the Ubuntu server I have them in has randomly locked up several times. I also bought a couple newer drives, and they show the same model number and PN (1ZD101-500) on the drive label, but the newer drives are labeled SC61. Putting their SNs into the Download Finder shows SC61 as an important update and the model number without the B. Has anyone tried updating the “B” disks with good results?
THANK YOU FOR THIS POST!
I was struggling with this one for a while.
I run 8x 10tb drives in ZFS RaidZ2 on LSI SAS2008 JBOD controllers on linux.
This appears to have fixed all my errors with these drives so far.
Thanks again for writing this blog post.
Hey that’s awesome, great to hear! I really love the drives, the firmware fix was certainly needed though, here no issues whatsoever since then too! 🙂
Hi there, thanks for this information. I bought 3 Seagate Expansion USB drives on Black Friday, shucked them for unRAID. Turns out they have similar issues as yours with my Dell Perc H310 HBA, flashed to IT mode. But mine are Barracuda Pro “ST10000DM0004-1ZC101”, not Ironwolf ST10000VN0004. So there’s no firmware update (yet).
FWIW, mine have firmware “DN01” and are dated with Apr 2019.
Anyway thanks again, wish I’d seen this earlier.
Did you ever get a for
The Barracuda pro’s…. same issue here!
I did not, did you check Seagates website?
Does this issue affect the 4tb seagate ironwolf non pros? ST4000VN008
No, I believe it does not
Hi.
I have same problem with completely new Seagate IronWolf NAS 8Tb drive ST8000VN004, dropping disk from ZFS on Qnap TS-h973AX NAS. I am running SeaTools for Windows on other computer and everything looks good, but NAS marked my drive with Warning, to many S.M.A.R.T. errors “Uncorrectable sector count”.
I just created POOL in raid 5 with 5 disks and started to copy data. This happened in first 8 hours of drive working.
I do not know what kind of controler is inside Qnap TS-h973AX NAS.
There is only SC60 firmware for 8Tb drive, no SC61. If there is any unofficial firmware anywhere, can you point please…
Exact same here!
Check this out, my ZFS system is a mix of HGST, WD, and Seagate. Every once in a while I experience random checksum failures on ZFS pools, ONLY for Seagate drives.
Behold:
“`
[Sat Jan 1 21:51:17 2022] sd 0:0:6:0: [sdg] tag#0 FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_OK
[Sat Jan 1 21:51:17 2022] sd 0:0:6:0: [sdg] tag#0 CDB: Read(16) 88 00 00 00 00 01 9c 00 28 40 00 00 00 08 00 00
[Sat Jan 1 21:51:17 2022] print_req_error: I/O error, dev sdg, sector 6912223296
“`
^ these are typically occurring and littered throughout logs.
culprits?
“`
$ for DISK in $(dmesg -T | grep ‘I/O error’ | awk ‘{print $10}’ | sort –unique | awk -F, ‘{print $1}’); do ll /dev/disk/by-id | egrep $DISK | grep -v part; done
lrwxrwxrwx 1 root root 9 Jan 2 00:09 ata-ST4000VN008-2DR166_ZGY8Z3F9 -> ../../sdd
lrwxrwxrwx 1 root root 9 Jan 2 00:09 wwn-0x5000c500c8e51e85 -> ../../sdd
lrwxrwxrwx 1 root root 9 Apr 2 2021 ata-ST4000VN008-2DR166_ZGY7G74K -> ../../sdg
lrwxrwxrwx 1 root root 9 Apr 2 2021 wwn-0x5000c500c6a2c721 -> ../../sdg
lrwxrwxrwx 1 root root 9 Jan 2 00:09 ata-ST4000VN008-2DR166_ZGY8Z37N -> ../../sdh
lrwxrwxrwx 1 root root 9 Jan 2 00:09 wwn-0x5000c500c8e52caa -> ../../sdh
lrwxrwxrwx 1 root root 9 Jan 2 00:10 ata-ST2000VN004-2E4164_W52480RK -> ../../sdk
lrwxrwxrwx 1 root root 9 Jan 2 00:10 wwn-0x5000c5009d407083 -> ../../sdk
lrwxrwxrwx 1 root root 9 Jan 2 00:10 ata-ST2000VN000-1H3164_W1H25JXM -> ../../sdl
lrwxrwxrwx 1 root root 9 Jan 2 00:10 wwn-0x5000c5006a406dab -> ../../sdl
“`
^ it’s ONLY seagate drives incurring these errors …
Same problem as above I have a bunch of 8TB Drives with CRC errors that are basically useless in any ZFS array, I won’t use anything but. So there is a $1000+ out the window until Seagate issues a fix.
This is one of the few places I’ve found talking about weirdness with Ironwolf drives.
I have a similar issue with a 10TB Seagate Non-Pro Ironwolf (ST10000VN0008-2PJ103 is the model, but with firmware SC61) in my arary, although I’m using SnapRAID & MergerFS instead of ZFS.
I get I/O errors during a Scrub or Sync sometimes on this one particular Seagate drive in my array. What’s unique about this drive, is that it has much more files than the others in my array (6 WD Reds, 1 Toshiba N300 & 1 Seagate Ironwolf – All 10TB models).
After I get the errors, if I do a tune2fs -l on the partition, it’ll tell me it’s “clean with errors”. Then I do an fsck on the partition, it finds some errors and fixes them, the issue goes away until randomly I’ll get the problem again, often several scrubs/syncs later. It seems to occur after writing a large amount of files to the Seagate drive only, all other drives have no issue.
I/O errors are usually related to the drive failing, but I’ve tried swapping the cable and the PSU but I still seem to get errors randomly. I’ve tried doing a badblocks -sv read only test on the entire drive and found no errors or bad sectors. What’s more, the files that show I/O errors are perfectly fine and without any errors after doing an fsck on the drive.
I’ve also tried several intensive checks of the data on the entire disk against the parity drives using “snapraid check”, and again found no errors. SMART data is clean, and extended SMART tests pass without issues. The only thing I haven’t tried is the destructive badblocks write test. I haven’t yet done this as there’s data on the drive.
The comment about the controller is interesting, I have my disks connected to a LSI SAS2308 HBA. I haven’t really tried connecting the drive to the motherboards SATA ports (ASRock X470D4U) to fully rule that out yet myself either. It may be the next thing I try.
All of this seems to point to the drive, but the randomness of getting the errors is weird. Usually a failing drive will consistently cough up errors in my experience.
are there any mirrors for these firmwares? they dont exist on seagate website
The download link for the firmware doesn’t work anymore. Any new link available? I can’t seem to find it.